

- jaro education
- 15, February 2024
- 11:00 am
In data wrangling, the transformations and aggregations take on diverse forms, often distinct from those performed during the Extract, Transform, Load (ETL) process. These adaptations cater specifically to the statistical needs of the data model, ensuring that the input data aligns seamlessly with the intended applications.
In this guide, we will know what data wrangling is and offer insights into the six essential steps constituting this indispensable process. Plus, with the blog, you will get to know about the prime role of data-wrangling software along with its differences from ETL processes.
What is Data Wrangling in Data Science?
Data wrangling stands as a pivotal practice in the repertoire of data analysts and scientists. It involves converting data from a flawed and unusable state into a more refined and compatible format, laying the groundwork for downstream applications. This transformative process is indispensable in unlocking the true value embedded within data, allowing for its optimal utilization.
The primary objective of data wrangling is to meticulously map, convert, and align raw data from its original format and structure to a more anticipated one, aligning with the requirements of diverse applications. The data wrangler is at the forefront of this operation, the skilled professional responsible for executing this crucial process, ultimately streamlining the data preparation phase and saving valuable time.
Essential Roles of Data Wrangling Software
Data wrangling software has several roles, which are discussed below.
1. Transforming Raw Data into Usable Form
Table of Contents
Data wrangling is about making raw data usable. It is the intricate process of refining and structuring data to ensure accuracy and reliability, laying the foundation for downstream analyses. By employing data wrangling techniques, organizations can be confident that high-quality data is entering their analytical pipelines, fostering more robust and dependable results.
2. Centralising Data from Diverse Sources
In the era of diverse data sources, data wrangling serves as a unifying force, ranging from databases to spreadsheets and beyond. It brings together data scattered across various sources into a centralized location. This consolidation simplifies data management and sets the stage for comprehensive analyses by providing a holistic view of the information.
3. Formatting Data for Business Relevance
The ability to piece together raw data according to specific formats and understand the business context is a hallmark of effective data wrangling. This ensures that data is not just processed but is aligned with the requirements and objectives of the business. Harmonizing data with business needs is essential for extracting meaningful insights that drive informed decision-making.
4. Automated Data Integration for Standardised Output
Automated data integration tools, a subset of data wrangling techniques, are crucial in cleaning and converting source data into a standard format. This standardization enables organizations to use the data repeatedly, facilitating cross-data set analytics. Businesses leverage this uniformity to gain comprehensive insights and uncover patterns that may be elusive when dealing with disparate data formats.
5. Cleansing Data from Noise and Flaws
Data, often laden with noise, errors, or missing elements, requires meticulous cleansing. Data wrangling is the guardian of data integrity, filtering out inconsistencies and flaws. The result is a more reliable, accurate dataset conducive to meaningful analyses.
6. Preparing for Data Mining
Data wrangling serves as the essential preparatory stage for the data mining process. Before extracting insights, the data must be refined and structured. This preparatory phase ensures the data is ready for exploration, paving the way for more effective data mining and subsequent knowledge discovery.
7. Empowering Timely Decision-Making
The significance of data wrangling lies in its ability to empower business users to make concrete, timely decisions. Data wrangling facilitates a more agile and responsive decision-making process by providing a refined and contextualized dataset, giving organizations a competitive edge in the dynamic business landscape.
A Comprehensive Exploration of the Six Essential Steps in Data Wrangling
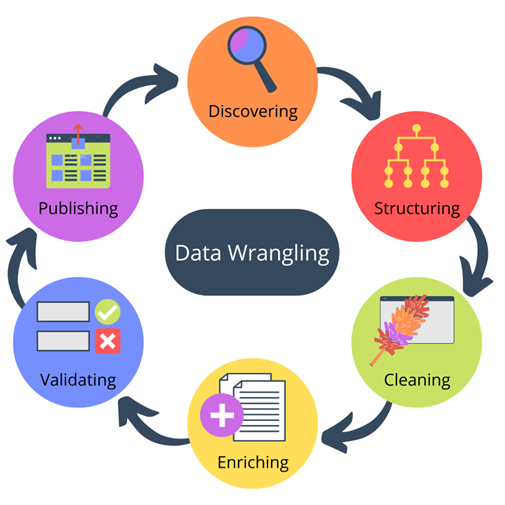
This comprehensive guide navigates through the six essential steps of the data wrangling process, shedding light on each phase and its significance in preparing data for downstream applications.
*vmblog.com
Step 1: Data Discovery
Data discovery marks the inaugural step in the data-wrangling process. This phase involves the understanding of the dataset, often collected from diverse sources in various formats. The primary objective is to compile disparate, siloed data sources and configure them for enhanced comprehensibility and analysis. The unstructured, raw data is akin to an unruly crowd. During the Data Discovery step, efforts are focused on organizing and aligning this data to uncover underlying patterns and trends.
Step 2: Data Structuring
During collection, raw data often lacks a defined structure, presenting a challenge for analytical purposes. In the data structuring phase, the dataset transforms to fit seamlessly into the analytical model adopted by the business. This restructuring allows for better analysis by parsing unstructured data, which may be text-heavy and include elements like dates, numbers, and ID codes. The parsing process involves extracting relevant information, resulting in a more organized and user-friendly dataset with columns, classes, and headings.
Step 3: Data Cleaning
While data wrangling and data cleaning are terms often used interchangeably, they represent distinct processes. Data cleaning, a crucial aspect of the overall data wrangling process, involves addressing errors in raw data before progressing to subsequent stages. This intricate process tackles outliers correctly and eliminates erroneous data by applying algorithms. Automating these algorithmic tasks is often achieved using tools such as Python and R. This enhances dataset cleanliness by removing outliers, standardizing data formats, identifying duplicate values, and validating data integrity.
Data Cleaning Objectives
- Removing outliers to prevent skewed results in data analysis.
- Changing null values and standardizing data formats for improved quality and consistency.
- Identifying and rectifying duplicate values, structural errors, and typos enhances data validity and ease of handling.
Step 4: Data Enriching
With a deep understanding of the data acquired during the earlier steps, data enriching becomes an optional yet valuable phase. This step involves augmenting the existing dataset with additional data from diverse sources, such as internal systems or third-party providers. The goal may be to accumulate more data points, enhance analysis accuracy, or fill gaps in the dataset. Data enrichment also contributes to a more comprehensive and robust dataset, aligning it further with specific analytical requirements.
Step 5: Data Validating
Data validation is a critical activity in addressing issues related to data quality. This step ensures that the data adheres to defined quality, consistency, accuracy, security, and authenticity rules. Repetitive programming processes, guided by preprogrammed scripts, verify attributes such as accuracy and the normal distribution of fields in datasets. The validation process plays a key role in both data cleaning and data wrangling, highlighting its significance in ensuring the overall quality and reliability of the dataset.
Data Validation Criteria
- Quality
- Consistency
- Accuracy
- Security
- Authenticity
Step 6: Data Publishing
As the final step in the data wrangling process, data publishing involves making the processed and refined data accessible for analytics. After completing the preceding steps, the data is deemed ready for consumption, and various options for publication are considered. This may involve depositing the data into a new architecture or database, paving the way for its use in gaining insights, generating business reports, and more. The possibilities extend to further processing the data to create larger and complex data structures, such as data warehouses, allowing for myriad analytical possibilities.
Unlocking Business Advantages with Data Wrangling
You can witness multiple business advantages by using data wrangling. The advantages or benefits of data wrangling are as follows:
1. Easy Analysis
At the heart of data wrangling lies its ability to empower Business Analysts and Stakeholders to conduct intricate analyses swiftly and effortlessly. Once raw data undergoes the transformative process of data wrangling, it emerges in a structured and organized format. This structured data, arranged in neat rows and columns, becomes easily digestible, facilitating quick and efficient analysis. This empowers decision-makers to glean insights from even the most complex datasets easily.
2. Simple Data Handling
Data wrangling is instrumental in transforming raw, unstructured, and messy data into a usable format. This conversion organizes the data and enriches it, adding depth and meaning. The result is a dataset that is neatly arranged and infused with intelligence, making it more meaningful and relevant. This simplicity in data handling ensures that analysts and stakeholders can navigate and extract insights without grappling with the complexities of disorganized data.
3. Better Targeting
Combining data from multiple sources becomes seamless through data wrangling, leading to a profound understanding of the target audience. This understanding, in turn, enhances targeting strategies for various business initiatives, such as advertising campaigns and content strategies. Whether aiming to showcase products or services through webinars or develop training courses using online platforms, having enriched and combined data is paramount for success. Data wrangling facilitates the synthesis of diverse datasets, providing a holistic view instrumental in shaping targeted and effective strategies.
4. Efficient Use of Time
The efficiency of the data wrangling process is particularly evident in the optimized use of analysts’ time. Analysts can redirect their efforts toward deriving valuable insights by alleviating the challenges associated with organizing unruly data. The time saved in data organization is, therefore, utilized more efficiently in making informed decisions based on data that is not only well-structured but also easy to read and comprehend.
5. Clear Visualisation of Data
Upon completing the data wrangling process, the transformed data can seamlessly be exported to any analytics visual platform. This flexibility allows businesses to summarise, sort, and analyze the data visually. Clear visualizations aid in understandably presenting complex information, facilitating better communication of insights within the organization. Whether using graphs, charts, or dashboards, the ability to visually represent data enhances the overall understanding and interpretation of key metrics.
*integrate.io
Essentials of Data Wrangling Tools
Automated tools for data wrangling offer a streamlined approach, allowing users to gather insights, validate data mappings, and scrutinize data samples at each stage of the transformation process. One of the noteworthy advantages of these tools is their ability to swiftly detect and correct errors in data mapping, enhancing the overall efficiency of the data preparation workflow. Automated data cleaning becomes necessary in scenarios where businesses deal with exceptionally large datasets, offering a rapid and scalable solution to address the complexities of extensive data sets.
Manual Data Cleaning Processes
The responsibility typically falls on the data team or data scientists for manual data cleaning processes. In these cases, professionals manually navigate the intricacies of data wrangling, employing their expertise to ensure accuracy and reliability. While more labor-intensive, manual data cleaning allows for a nuanced approach, often preferred in scenarios where specific requirements or domain knowledge are crucial for effective data preparation. In smaller setups, non-data professionals may also be entrusted with cleaning data before leveraging it for analysis.
Examples of Data Wrangling Tools
Spreadsheets / Excel Power Query
This classic tool remains a basic manual data wrangling staple. Excel’s Power Query functionality provides users with a user-friendly interface for importing, transforming, and cleaning data, making it accessible to a broad spectrum.
OpenRefine
Geared towards users with programming skills, OpenRefine is an automated data cleaning tool. Its capabilities extend to transforming and structuring data efficiently, offering a versatile solution for those well-versed in programming languages.
Tabula
Suited for handling diverse data types, Tabula serves as a versatile data wrangling tool. Its functionalities encompass gathering, importing, and cleaning data, making it adaptable to various data preparation scenarios.
Google DataPrep
As a comprehensive data service, Google DataPrep stands out by exploring, cleaning, and preparing data. Its intuitive interface facilitates an accessible approach to data wrangling, particularly for users seeking a user-friendly solution.
Data Wrangler
Positioned as a data cleaning and transforming tool, Data Wrangler caters to users seeking a versatile solution. Its capabilities extend to basic and advanced data-wrangling tasks, contributing to a holistic approach to data preparation.
Mastering Data Wrangling with Python for Machine Learning
Data wrangling with Python’s Pandas framework plays an important role in different aspects of data analysis. Pandas, an open-source library, facilitates various data wrangling tasks essential for efficient data processing. Key functionalities include data exploration, where the dataset is comprehensively studied and visualized to gain insights. Handling missing values is crucial, often involving replacement with means, modes, or dropping rows containing NaN values.
Reshaping data is another critical aspect, enabling manipulation and modification of data to meet specific requirements. This process ensures the inclusion of new data or adjustments to existing data. Filtering data addresses the removal of unwanted rows or columns, enhancing the dataset’s relevance and efficiency.
On the other hand, Data wrangling in machine learning involves preparing a refined dataset for tasks like model training, analysis, and visualization. Through these procedures, the raw dataset is transformed into a more structured and purposeful form, laying the foundation for successful machine learning applications. Python’s Pandas framework simplifies these data wrangling processes, making it a versatile tool for data scientists and analysts alike.
Distinguishing Data Wrangling from ETL Processes
Data wrangling and ETL (Extract, Transform, Load) are distinct data processing methodologies, each serving specific purposes with notable differences.
ETL: Bridging Source Systems and Reporting Layers
ETL, an acronym for Extract, Transform, and Load, functions as a middleware process. This involves extracting data from diverse sources, transforming it through various operations according to business rules, and loading the processed data into target systems. Typically, ETL is employed for populating flat files or relational database tables. DW/ETL developers primarily utilize this process to link source systems with reporting layers.
Data Wrangling: Navigating Varied and Complex Datasets
Data wrangling, on the other hand, caters to a different user base, including analysts, statisticians, business professionals, executives, and managers. It revolves around the intricate handling of varied datasets, often within the context of exploratory data analysis.
Key Differences
Several factors differentiate these processes. Firstly, in terms of users, data wrangling is embraced by analysts and business professionals, while ETL is mainly used within the domain of DW/ETL developers. Secondly, the data structures they handle differ; data wrangling deals with diverse and complex datasets, whereas ETL focuses on structured or semi-structured relational datasets. Finally, while data wrangling is primarily used for exploratory data analysis, ETL is specifically designed for the gathering, transformation, and loading of data to facilitate reporting.
Final Thoughts
The six essential steps of data wrangling form a comprehensive framework that transforms raw, chaotic data into a refined, usable state. Each step plays a distinct role, from understanding and organizing raw data to enhancing its quality, validating its integrity, and making it accessible for analytical exploration. Data wrangling is not just a technical process but a strategic endeavor that empowers data analysts and scientists to extract valuable insights from the vast sea of information, contributing significantly to informed decision-making and business success.
If in case, you are interested in getting into data science field, then you must consider enrolling in the Executive Programme in Applied Data Science with Machine Learning & Artificial Intelligence by CEP, IIT Delhi. This course addresses the demand for data wrangling by arming executives and professionals with vital skills. Participants gain a thorough understanding of the fundamental principles of data science, machine learning algorithms, and artificial intelligence techniques, focusing on practical application in real-world scenarios. It further catalyzes business growth and fosters innovation, empowering professionals to adeptly leverage the potential of these technologies within their respective industries.
Trending Blogs






