
The Ultimate Guide to Data Science: Everything You Need to Know in 2025
Table Of Content
Introduction
1. What is Data Science?
4. Data Science Course Syllabus
5. Skills Required for Data Science
6. Tools and Technologies in Data Science
7. Career Opportunities in Data Science
8. Educational Pathways to Become a Data Scientist
9. Challenges in Data Science and How to Overcome Them
10. Future Trends in Data Science
11. How Jaro Education Can Help
Final Thoughts
Frequently Asked Questions
Introduction
1. What is Data Science?
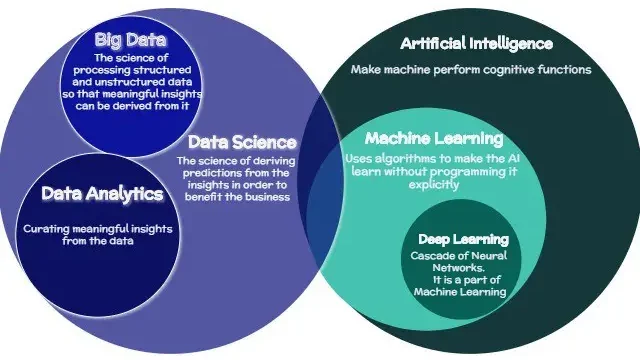
The terms Data Science, Artificial Intelligence (AI), Machine Learning (ML), and Data Analytics are often used interchangeably, but they represent distinct concepts. Understanding their differences is essential to grasp the scope and applications of Data Science.
- Data Science is the overarching field that encompasses the entire process of working with data, from collection to analysis and interpretation. It includes elements of AI, ML, and Data Analytics but also involves data engineering, visualisation, and storytelling. Data Scientists focus on identifying patterns, building models, and deriving insights that inform business decisions.
- Artificial Intelligence (AI) refers to the broader goal of creating systems that mimic human intelligence. AI enables machines to perform tasks like reasoning, problem-solving, and decision-making. While Data Science leverages AI techniques, AI itself is a separate field with applications that go beyond data analysis—such as robotics, natural language processing, and computer vision.
- Machine Learning (ML) is a subset of AI focused on building algorithms that allow machines to learn from data without being explicitly programmed. It’s a critical tool within Data Science, enabling predictive and prescriptive analytics. For instance, a Data Scientist might use ML algorithms to forecast stock prices or identify fraudulent transactions. However, ML requires clean, structured data, which is often a byproduct of the broader Data Science process.
- Data Analytics is a more focused subset of Data Science, concerned primarily with examining datasets to identify trends, patterns, and anomalies. While Data Science takes a holistic approach to solving problems, Data Analytics often has a narrower scope, addressing specific questions like “What happened?” or “Why did it happen?”

4. Data Science Course Syllabus
5. Skills Required for Data Science
- Critical Thinking
Data Scientists must be able to analyse problems from multiple perspectives, identify patterns, and generate actionable insights. Critical thinking aids in developing hypotheses and interpreting results accurately.
- Communication
Explaining complex concepts to non-technical stakeholders is essential. Data Scientists must translate data findings into clear, actionable insights through reports, visualisations, and presentations.
- Collaboration
Data Science projects often involve cross-functional teams. Working seamlessly with engineers, analysts, and business professionals requires strong teamwork and adaptability.
- Problem-Solving
A Data Scientist must be adept at defining problems, identifying data-driven solutions, and iterating until the desired outcome is achieved. Creativity in approach and resilience in troubleshooting are critical.
- Time Management
With multiple tasks such as data cleaning, model building, and result validation, efficient time management ensures deadlines are met without compromising quality. - Business Acumen
Understanding the industry context is vital for aligning data projects with organisational goals. A Data Scientist must know how to identify relevant problems and measure the impact of their solutions.
By combining technical expertise with interpersonal skills, Data Scientists bridge the gap between raw data and impactful decision-making.
6. Tools and Technologies in Data Science
7. Career Opportunities in Data Science

Coming to the question of how to become a data scientist, breaking into Data Science may seem challenging, but with the right strategy, you can secure your dream role:
- Build a Strong Foundation: Develop expertise in programming, statistics for data science, and machine learning through courses, certifications, or self-study.
- Create a Portfolio: Showcase your skills through projects that demonstrate your ability to handle real-world data. Kaggle competitions and GitHub repositories are excellent platforms for building a portfolio.
- Leverage Networking: Attend Data Science meetups, webinars, and conferences to connect with industry professionals. Networking often leads to job referrals.
- Gain Practical Experience: Internships, freelance projects, or volunteering for data-related tasks can help you gain hands-on experience.
- Tailor Your Resume: Highlight your technical skills, tools, and relevant projects in your CV. Use keywords aligned with job descriptions to stand out.
- Prepare for Interviews: Data Science interviews often include coding challenges, problem-solving exercises, and case studies. Practice mock interviews to build confidence.

8. Educational Pathways to Become a Data Scientist
9. Challenges in Data Science and How to Overcome Them
- Data Quality Issues
Poor-quality data is one of the biggest obstacles for Data Scientists. Inconsistent, incomplete, or inaccurate data can lead to unreliable models and flawed insights. Issues like missing values, duplicate entries, and unstructured formats complicate the data preparation process.
- Data Accessibility
Access to relevant and sufficient data can be limited due to organizational silos, privacy laws, or technical barriers. Many businesses struggle with integrating data from multiple sources like legacy systems, APIs, and cloud platforms.
- Complexity of Data
Modern data is vast, unstructured, and highly diverse. Dealing with images, videos, text, and real-time streams demands advanced tools and methodologies. Analyzing such data without adequate infrastructure becomes a daunting task.
- Skill Gaps
Despite growing interest in Data Science, many professionals lack expertise in areas like machine learning, big data tools, and cloud computing. This skills shortage hampers project execution and innovation.
- Model Deployment and Scalability
Building machine learning models is one part of the equation. Deploying those models into production and ensuring they scale to real-world scenarios is another major challenge, especially in dynamic business environments. - Ethical and Legal Issues
Data privacy laws like GDPR and CCPA impose strict regulations on how data can be collected, stored, and analyzed. Missteps in adhering to these laws can lead to legal complications and reputational damage.
10. Future Trends in Data Science
11. How Jaro Education Can Help
Final Thoughts
Frequently Asked Questions
- The salary of a Data Science professional depends on factors like experience, location, industry, and the type of course completed. Entry-level professionals can expect an average annual salary of ₹5–8 lakhs in India. With a few years of experience, mid-level roles like Data Analysts or Machine Learning Engineers earn between ₹10–20 lakhs annually. Senior-level roles, such as Data Science Managers, can command salaries exceeding ₹30 lakhs per year.
- Globally, the demand for skilled Data Scientists is high, with professionals earning competitive salaries in markets like the US, Europe, and Australia. Completing a well-recognised course, such as those offered by IIM Kozhikode or IIT Madras Pravartak in partnership with Jaro Education, can significantly boost earning potential by equipping learners with industry-relevant skills and certifications.
- Yes, coding is an integral part of Data Science, as it enables professionals to manipulate and analyze data effectively. Programming languages like Python, R, and SQL are commonly used for tasks such as data cleaning, statistical modeling, and machine learning implementation.
- However, the level of coding expertise required depends on the role. For instance, Data Analysts may only need basic SQL and Excel skills, while Data Scientists and Machine Learning Engineers require proficiency in advanced programming concepts.
- The good news is that many Data Science courses are designed to teach coding from scratch. Tools like Jupyter Notebook and drag-and-drop platforms also make it easier for beginners to perform Data Science tasks without extensive coding knowledge. With consistent practice, anyone can master the programming skills needed for Data Science.
- Data Science welcomes learners from diverse academic and professional backgrounds, but certain qualifications and skills are essential for success. Generally, a bachelor’s degree in fields like mathematics, statistics, computer science, or engineering provides a strong foundation. However, many programs also accept professionals from other domains if they meet specific prerequisites.
- In addition to academic qualifications, some essential skills for Data Science include programming (Python, R, or SQL), statistical knowledge, and a basic understanding of machine learning concepts. Professionals with experience in business analysis, IT, or software development may find transitioning to Data Science easier.
- Many institutions offer beginner-friendly courses, making it possible for individuals with little or no prior experience to enter the field. With the right training, even those from non-technical backgrounds can build a successful career in Data Science.
- Choosing between Computer Science (CS) and Data Science (DS) depends on your career goals and interests. CS focuses on building and maintaining computer systems, including software development, algorithms, and networking. It provides a strong foundation in programming and computational theory, making it ideal for careers in software engineering, cybersecurity, or system architecture.
- On the other hand, Data Science emphasizes extracting insights from data. It combines analytical skills, statistical knowledge, and programming to solve real-world problems. If you’re passionate about working with data, AI, or machine learning, DS may be the better choice.
- Ultimately, both fields offer excellent career opportunities. While CS offers broader applications in technology, DS is more niche, catering to the growing demand for data-driven decision-making. Your choice should align with your interests and the skills you wish to develop.
- While Data Science is closely related to IT, it is not exclusively an IT job. Instead, it intersects multiple disciplines, including business analytics, machine learning, and data engineering. The role of a Data Scientist often requires collaboration with IT teams, but the focus is broader, emphasizing data-driven decision-making.
- Data Science roles vary depending on the industry and organisation. In some cases, Data Scientists work alongside IT professionals to implement data pipelines and manage databases. In other cases, they act as independent analysts or strategists, using data to address business challenges.
- It’s important to note that not all IT professionals are Data Scientists. While IT jobs often focus on infrastructure, software development, and network management, Data Science dives deep into interpreting data to predict trends and optimise performance.
- Data Science is a multidisciplinary field that extracts meaningful insights from structured and unstructured data using a combination of mathematics, statistics, programming, and domain expertise. It involves various processes, including data collection, cleaning, analysis, and visualization, to uncover patterns and trends that can inform decision-making.
- Data Scientists use techniques like machine learning, predictive analytics, and artificial intelligence (AI) to solve complex problems and provide actionable insights. For example, in e-commerce, Data Science helps in recommending products, while in healthcare, it enables early diagnosis and personalized treatment plans.
- In essence, Data Science bridges the gap between raw data and strategic business decisions. It empowers organisations to understand their customers, optimise operations, and innovate in competitive markets. The field is ever-evolving, making it an exciting and lucrative career choice

