HOME > BLOG > AI and Machine Learning > Introduction to Machine Learning with Scikit-Learn: Building Predictive Models in Python
AI and Machine Learning
Introduction to Machine Learning with Scikit-Learn: Building Predictive Models in Python
J
By Dr. Sanjay Kulkarni
April 18, 20257 min read
Last updated on March 18, 2026
SHARE THIS ARTICLE
Table Of Content
What is Machine Learning?
Advantages of Machine Learning
What is Sci-kit Learn?
What is a Predictive Model?
Computers can now learn from and make predictions based on large datasets thanks to machine learning, which is a disruptive force in the era of data-driven decision-making. Among this chaos of vast datasets lies software in the library of machine learning that is used by Python programmers. The software is identified as scikit-learn.
Scikit-learn is a program that practitioners and scholars alike turn to for a smooth introduction to the field of machine learning because of its user-friendly interface and extensive library of algorithms. Scikit-learn offers an extensive toolset for processing a wide range of tasks quickly and effectively, from clustering and dimensionality reduction to classification and regression. To understand more about machine learning with sci-kit-learn, continue reading this blog.
What is Machine Learning?
A subfield of artificial intelligence known as “machine learning” creates algorithms by discovering hidden patterns in datasets and using those patterns to anticipate new data similar to the old one without the need for explicit task programming. Numerous applications, including picture and audio recognition, natural language processing, recommendation engines, fraud detection, portfolio optimization, automated tasks, and more, employ machine learning. Autonomous cars, drones, and robots are also powered by machine learning models, which enhance their intelligence and ability to adjust to changing surroundings.
In several sectors, such as e-commerce, social media, and online advertising, personalized suggestions based on machine learning are becoming increasingly common since they may improve user experience and boost platform or service engagement.
Hence, making recommendations has been a common task performed with the help of machine learning. It is frequently used in recommender systems, which analyze past data to provide consumers with individualized recommendations. Another kind of machine learning that may be applied to enhance recommendation-based systems is reinforcement learning. With reinforcement learning, an agent can make judgments based on input from its surroundings, which may be used to enhance the suggestions it makes to users.
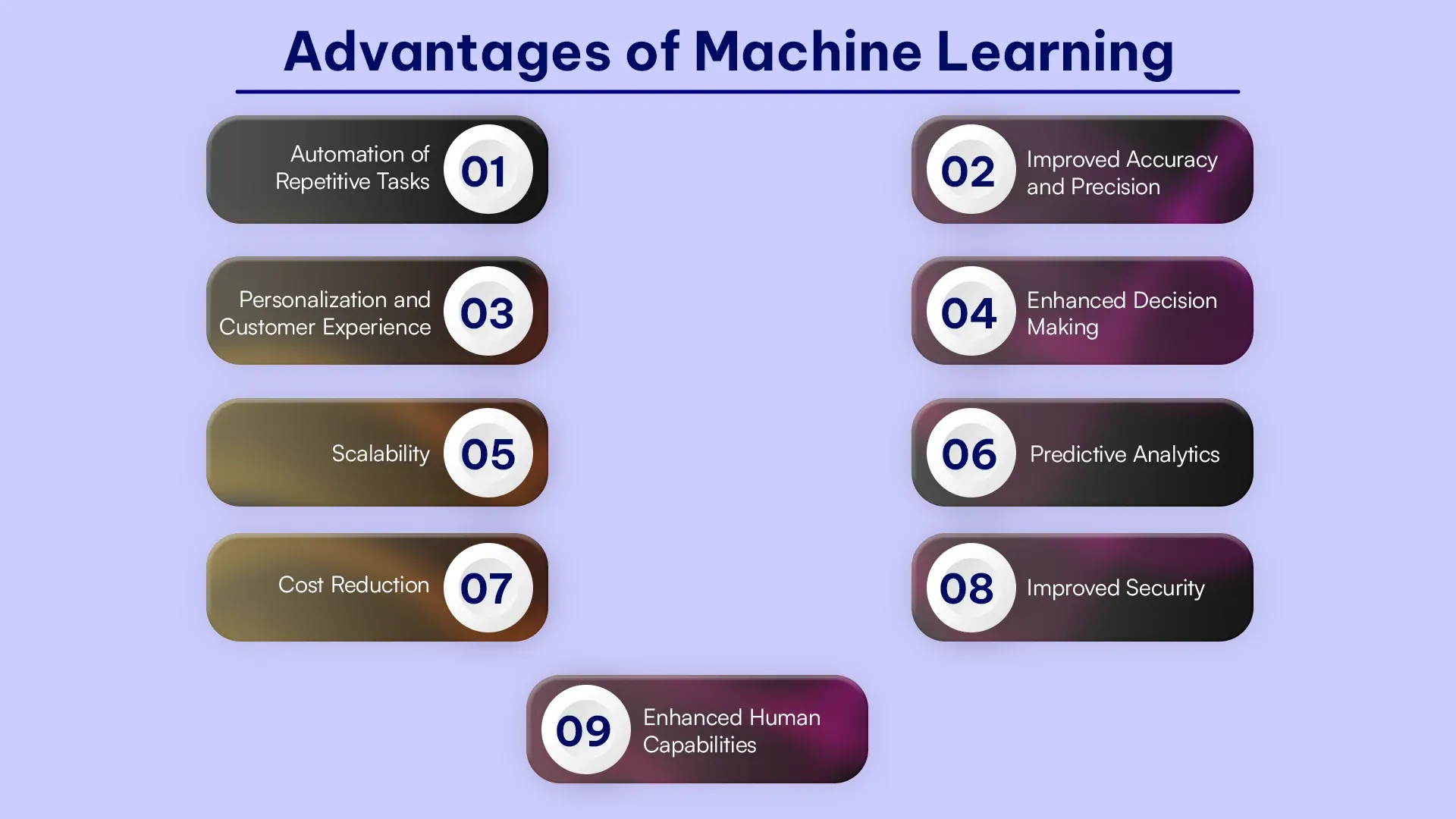
Advantages of Machine Learning
Machine Learning is known to address issues, aid businesses by making forecasts, and assist them in making better decisions. Here are some of the advantages that are related to machine learning:
Machine learning may review large amounts of data and help us identify certain trends and patterns that cannot be performed manually.
In dynamic or unpredictable contexts, machine learning algorithms perform well when processing multi-dimensional and multi-variety data.
Machine learning refers to granting machines the capacity for self-learning, which enables them to provide predictions and automatically enhance algorithms.
The accuracy and efficiency of machine learning algorithms continue to increase with experience. This enables them to make wiser choices.
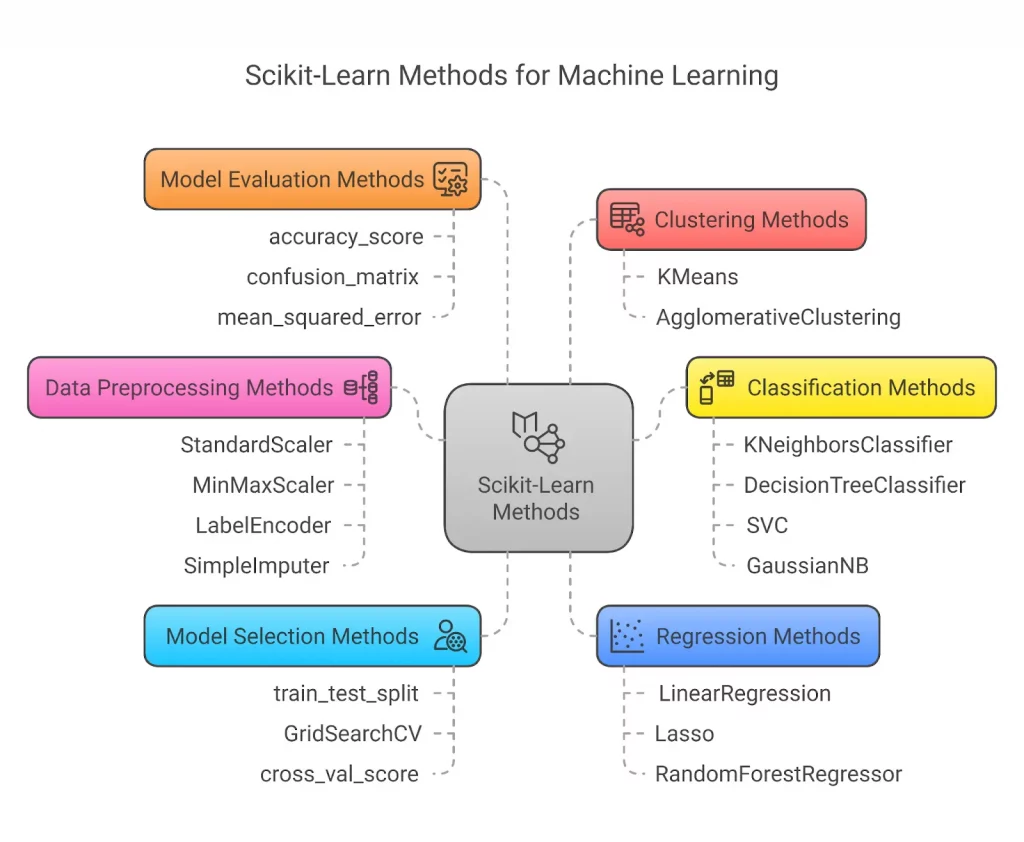
For Python machine learning, the most reliable and practical library is scikit-learn. It offers a range of effective techniques for statistical modeling and machine learning, including dimensionality reduction, regression, clustering, and classification, through a Python consistency interface. Simply put, a collection of supervised and unsupervised learning algorithms in Python is called Scikit-learn, and it is built on technologies such as Pandas, Matplotlib, and NumPy.
Certain functionalities are widely used in Sci-kit Learn software. Some of those well-known functionalities are discussed below:
1. Linear Regression
Linear regression is employed for regression tasks, especially the prediction of continuous output. In linear regression and statistical modeling, a linear function depicts the connection between input variables and a scalar response variable.
2. Logistics Regression
A straightforward classification model that can predict binary or even multiclass output is called logistic regression. The testing and training of the dataset follow a similar logic to that of linear regression.
3. Random Forests
Random decision trees, or random forests, are statistical models used for both regression and classification applications. In essence, random forests are collections of questions and answers regarding the data arranged in a form that resembles a tree.
By using these questions, the data is divided into subgroups so that the data in each subsequent subgroup can be easily compared to one another.
4. Clustering
Clustering is the process of assembling comparable data items into groups according to their shared traits or attributes. The goal of clustering algorithms is to divide a dataset into groups or clusters so that the data points in a given cluster are more similar to one another than they are to those in other clusters.
Exploratory data analysis, pattern identification, and data segmentation are three frequent uses for this unsupervised learning approach.
5. Dimensionality
The term “dimensionality” describes how many aspects or qualities are included in each data point inside a dataset. The complexity and processing demands of the model are strongly impacted by the dimensionality of the data while working with machine learning methods.
By lowering the feature count while keeping as much pertinent data as feasible, sci-kit-learn’s dimensionality reduction algorithms seek to address these issues.
6. Classification
The process of assigning a new observation’s class or category based on its features is referred to as classification. The job of classification involves supervised learning, wherein the algorithm is taught using a labeled dataset that comprises input characteristics and their associated target labels.
What is a Predictive Model?
A popular statistical method for forecasting future behavior is predictive modeling. Data-mining technologies such as predictive modeling solutions analyze historical and present data to create a model that can forecast future events. Predictive modeling involves gathering data, developing a statistical model, making predictions, and validating (or updating) the model in light of new information.
Also, Predictive models determine the likelihood that a consumer will engage in a particular behavior in the future by evaluating historical performance. This category also includes models that look for minute trends in data to address customer performance-related queries.
An enthusiastic individual might be curious about how to build a predictive model in Python. To solve this problem, here are the series of steps that are required to build a predictive model in Python:
Step 1: In the initial step, the required data must be imported and explored according to the project’s requirements. Hence, the data must be loaded in the program.
Step 2: Once the data is loaded, the description and contents of the dataset must be explored.
Step 3: To obtain better accuracy in results, there must be a correlation among the datasets. In this step, a descriptive statistics algorithm is applied to obtain a clear understanding of the Python data model.
Step 4: Machine learning may require improved characteristics to be developed and trained before it can function well on novel tasks. Enhancing model performance and simplifying and expediting data processing can be achieved through the creation of novel features through feature engineering.
Step 5: Make sure your data collection process is in line with your prediction model before moving further. After gathering the data, analyze and improve it until you locate the details needed for your Python modeling.
Step 6: Selecting an appropriate variable is solely determined by the Python data model that has been created to perform the predictive analytics model.
Step 7: To find the best prediction algorithm, the dataset must now be divided into smaller pieces and tested using several new algorithms.
Step 8: To enhance the overall performance, slight changes can be made to the Python model’s hyperparameter.
Step 9: At the end, the final model is evaluated based on its performance in predicting the desired outcome.
Conclusion
Businesses look for ways to provide goods and services to congested marketplaces with an advantage as competition intensifies each day. In this situation, predictive models backed by data can help these businesses find novel solutions to persistent problems. Hence, to solve the problems of various entrepreneurs, a strong entry point has been made into the world of data-driven decision-making and predictive analytics, which is machine learning with scikit-learn. Scikit-learn’s user-friendly interface, strong algorithms, and comprehensive documentation enable practitioners of all skill levels to effectively use machine learning’s potential for diverse uses.
Since the study of machine learning requires gaining knowledge about a few technicalities, it is advisable to learn about such concepts from an esteemed institute. If you are interested in learning the concepts of machine learning, then you must join the Executive Certification in Advanced Data Science & Applicationsby IITM Pravartak – Technology innovation hub of IIT Madras. This extensive programme is designed for professionals looking to harness the power of data-driven insights with the help of cutting-edge methods, tools, and strategies required to address real-world data difficulties. It will equip you with the knowledge that you may require to succeed in the quickly changing field of data science and analytics, regardless of your level of experience.
Frequently Asked Questions
Scikit-learn is a popular open-source Python library used for machine learning. It provides simple and efficient tools for tasks like classification, regression, clustering, and dimensionality reduction. Built on libraries like NumPy, Pandas, and Matplotlib, it is widely used by beginners and professionals for building machine learning models.
Scikit-learn is widely used because of its easy-to-use interface, extensive documentation, and powerful built-in algorithms. It allows developers to quickly build, train, and evaluate machine learning models without needing complex coding, making it ideal for both beginners and experts.
Machine learning is used in various real-world applications such as recommendation systems (Netflix, Amazon), fraud detection, image and speech recognition, healthcare predictions, autonomous vehicles, and personalized marketing. It helps businesses make data-driven decisions and improve efficiency.
Building a predictive model using Scikit-learn involves a structured approach where you first import and understand your dataset, then clean and preprocess the data to make it suitable for analysis. After that, feature engineering is applied to improve model performance. The dataset is then split into training and testing sets, followed by selecting and training an appropriate machine learning algorithm. Once trained, the model is evaluated using performance metrics, and finally, hyperparameters are tuned to enhance accuracy and overall efficiency.
Dr. Sanjay Kulkarni
Data & AI Transformation Leader
Dr. Sanjay Kulkarni is a Data & AI Transformation Leader with over 25 years of industry experience. He helps organizations adopt data-driven and responsible AI practices through strategic guidance and education. With experience across startups and global enterprises, he bridges the gap between theory and real-world application. His work empowers teams to innovate and thrive in AI-driven environments.
Get Free Upskilling Guidance
Fill in the details for a free consultation
Related Courses
Explore our programs
Admission Closed
Achieving Excellence in Marketing: Programme for Marketing Leadership



 Admission Closed
Admission Closed

 Admission Open
Admission Open Admission Closed
Admission Closed Admission Closed
Admission Closed



