Data Structure: Binary, AVL, Red-Black Tree & Their Applications
J
By Jaro Education
April 18, 20237 min read
Last updated on March 20, 2026
SHARE THIS ARTICLE
Table Of Content
Definition of Data Structure
Understanding Various Data Structures and Their Applications
Binary Tees- Foundations and Operations
AVL Trees- Balancing Efficiency and Height
Data structures in computer science help in forming the very foundation of efficient programming and algorithm design. It is quite important to understand what a data structure actually is: it is a systematic way of organizing and managing data for storing and retrieving information efficiently. An inappropriate structure can make even the most powerful algorithms slow and inefficient.
There are several types of data structure, each designed to handle specific computational needs. Among them, the most involved in maintaining hierarchical data and providing efficient searching include binary trees, AVL trees, and red-black trees. These tree-based data structures ensure a balance in the way data is stored and retrieved for optimal performance of the data lookup, insertion, and deletion processes.
From database indexing to memory management, file systems, and finally to AI decision trees, applications of data structure are vast and power nearly every software system in use today. Understanding how each type of tree actually works will help the developer choose the right approach for solving a particular problem. Professionals will be able to make faster, smarter, and more reliable computing systems by mastering the application of a data structure such as binary, AVL, and red-black trees.
Definition of Data Structure
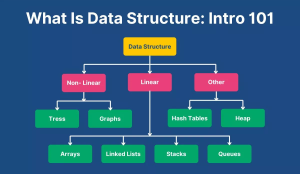
Data structure refers to a way of organizing and managing data in a specific format for efficient storage and retrieval. In simple terms, a data structure describes how data elements are related to each other and how various operations are performed, including insertion, deletion, traversal, and searching. It acts as the backbone of programming, which allows developers to handle large volumes of data with optimized performance. Arrays, linked lists, stacks, queues, trees, and graphs are some of the different varieties of data structures, each employed according to the nature of the problem that is to be solved.
*Unstop
Understanding Various Data Structures and Their Applications
Binary, AVL, and Red-Back trees form the foundation of data structure. Read further and acknowledge what they stand for and how they help developers to store and manipulate data.
Binary trees have a hierarchical structure where nodes are connected by edges. Every node can have a maximum of 3 children; one will be the left child, and the other one will be the right child. Here, the uppermost node is termed root, and the lowermost nodes are called leaves. Their applications are numerous, as they can be utilised for data storage and retrieval, along with network routing and evaluation of the expression. Insertion is one of the prime operations done by binary trees. When some new element is inserted in the binary tree, they are compared to the current nodes to choose between left and right according to their value. The process continues recursively till an appropriate insertion spot in the node is found. If the tree is properly balanced, insertion can be achieved in logarithmic time complexity, ensuring efficient updates to the structure.
By leveraging the tree’s hierarchical structure, one can effectively navigate into the nodes. This makes it easier to compare the target values with current nodes for proceeding to the left or right node accordingly. These traversal methods play a major role in various algorithms, like binary tree sorting, expression evaluation, and constructing expression trees.
Named after the inventors Adelson-Velsky and Landis, AVL trees are self-balancing binary trees. These trees can maintain a near-optimal balance between height and efficiency. Basic binary trees have some limitations that the AVL trees address. It ensures the difference between the heights of right and left subtrees does not exceed one. The prime difference between binary and AVL trees is that the latter has self-balancing properties, unlike the former. AVL trees perform rotations and restore balance whenever some imbalance happens due to an insertion or deletion operation. This helps in restoring near-optimal height. The rotations can be either single or double; it depends on the specific case. Plus, it requires rearranging the nodes to maintain the desired balance factor. This feature helps AVL trees to search, insert, and delete operations effectively.
AVL trees’ balancing act has added advantages. They help in reliable search operations, suitable for various scenarios, especially when fast retrieval of data is essential. With that, AVL trees are ideal for a dynamic environment where updates and modifications happen frequently. This is because they have the potential to minimise risks associated with performance degradation and the ability to restore balance after certain changes are made quickly.
Red-Black Trees- Data Balance and Flexibility
These flexible data structures can maintain balance besides accommodating simultaneous insertions and deletions. Rudolf Bayer and Volker Strassen collaboratively developed this masterpiece to have an uncompromised, fully balanced, and flexible structure appropriate for a dynamic environment. Like AVL trees Red-Black trees are self-balancing that enforce additional constraints on top of the binary tree structure. Each node in a Red-Black tree is assigned a colour, either red or black, which determines the tree’s balance. These colour properties, combined with specific rules, ensure that the tree remains balanced. Moreover, the longest path from the root to any leaf is no more than twice as long as the shortest path.
The flexibility of Red-Black trees makes them suitable for a wide range of applications. They are commonly used in data storage systems, as their balanced structure enables efficient indexing and search operations. Red-Black trees are also employed in network routing algorithms, graph algorithms, and various computational geometry problems.
Binary vs AVL vs Red-Black Tree: Key Differences
When it comes to structures such as Binary, AVL, and Red-Black Trees, their efficiency, balancing, and performance come in as key aspects of comparison. Data structure applications depend significantly on how quickly data may be inserted, deleted, or searched. Here’s a breakdown of their key differences.
Balancing Mechanism:
Binary Search Tree: Not self-balancing; it can be skewed.
AVL Tree: At each insertion or deletion, it is strictly balanced using rotation.
Red-Black Tree: Loosely balanced by color properties – red and black nodes.
Time Complexity (Search/Insert/Delete):
Binary Tree: O(n)-inefficient in case of large data sets.
AVL Tree: O(log n) – Excellent for Search Operations.
Red-Black Tree: O(log n) – efficient and consistent performance.
Efficiency of Insertion/Deletion:
Binary Tree: It is slower for large datasets because of imbalance.
AVL Tree: Moderate balancing overhead after updates.
Red-Black Tree: Relaxed rules on balancing allow faster insertions and deletions.
Use Cases:
Binary Tree: A simple hierarchical storage or expression evaluation.
AVL Tree: Databases, memory indexing, and high-speed lookups.
Red-Black Tree: Compilers, OS kernels, and system libraries.
Each of these types of data structures serves a different performance objective. Binary Trees are simple and intuitive, AVL Trees offer strict balancing for quick lookups, and Red-Black Trees optimize real-time performance. The choice depends on the application of data structure and system requirements.
Applications of data structure are important in computer science for efficient computation and problem-solving.
Every domain, ranging from databases to artificial intelligence, uses a specific type of data structure for effective data management and processing.
Trees, such as Binary and AVL, form the basis of most indexes used in databases for searching purposes.
Graphs and queues improve network communication, route algorithms, and data communication systems.
Stacks and arrays are essential in the evaluation of expressions, handling recursion, and memory management.
Operating systems use data structures for process scheduling and resource allocation.
Compiler design relies on trees and stacks in syntax analysis and code optimization.
AI uses tree and graph structures for decision-making and search algorithms.
Understanding the applications of data structure helps developers choose the right model for handling large volumes of data efficiently.
The mastery of different data structure applications certainly implies better time management, scalability, and overall system performance.
Conclusion
The utilisation of the right data structures helps to optimise algorithms to solve complex problems and enhance performance. Binary Trees, AVL Trees, and Red-Black Trees stand out as prime components with their unique features and applications. By understanding their foundations, mechanisms, and real-world applications, developers can harness the power of these data structures. These enable developers to tackle complex challenges and create innovative solutions.
To master data structure, you can enroll now via Jaro Education’s platform for the online BCA programme from the renowned Manipal University Jaipur. With the help of Jaro, you can avail one-on-one counselling session to learn about the program and how it can suit you. Additionally, you get excellent placement assistance, top-notch faculty members, learning resources, and much more to get started on your learning journey.
Frequently Asked Questions
A data structure is a way of arranging or structuring data in memory for efficient storage so that it can be easily accessed and modified. The definition of a data structure includes the relationships among data elements and the operations applicable, such as insertions or searches.
The major types of data structure are Linear (like arrays, stacks), Non-linear (like trees, graphs), Homogeneous, and Non-homogeneous. Each type of data structure serves different computational needs and optimizes performance for particular problems.
A data structure in C is a way of managing and processing data efficiently using arrays, linked lists, stacks, and trees. Such applications of data structures in C provide speed and efficiency in memory utilization while executing a program.
The main role of a data structure is to organize and store data to ensure optimal access, modification, and storage. Understanding applications of data structure helps developers choose the right one to improve algorithm performance and scalability.




 Admission Open
Admission Open Admission Open
Admission Open





